Optical character recognition in PDF
Optical character recognition allows converting images containing text to editable PDF text format, which supports document text search, copying, edition and all other PDF text functionality. Text recognition can be performed only if it is not locked in PDF document permissions.
Optical text recognition in Master PDF Editor is based on Tesseract’s neural network models, which allows for more accurate character detection in scanned documents.
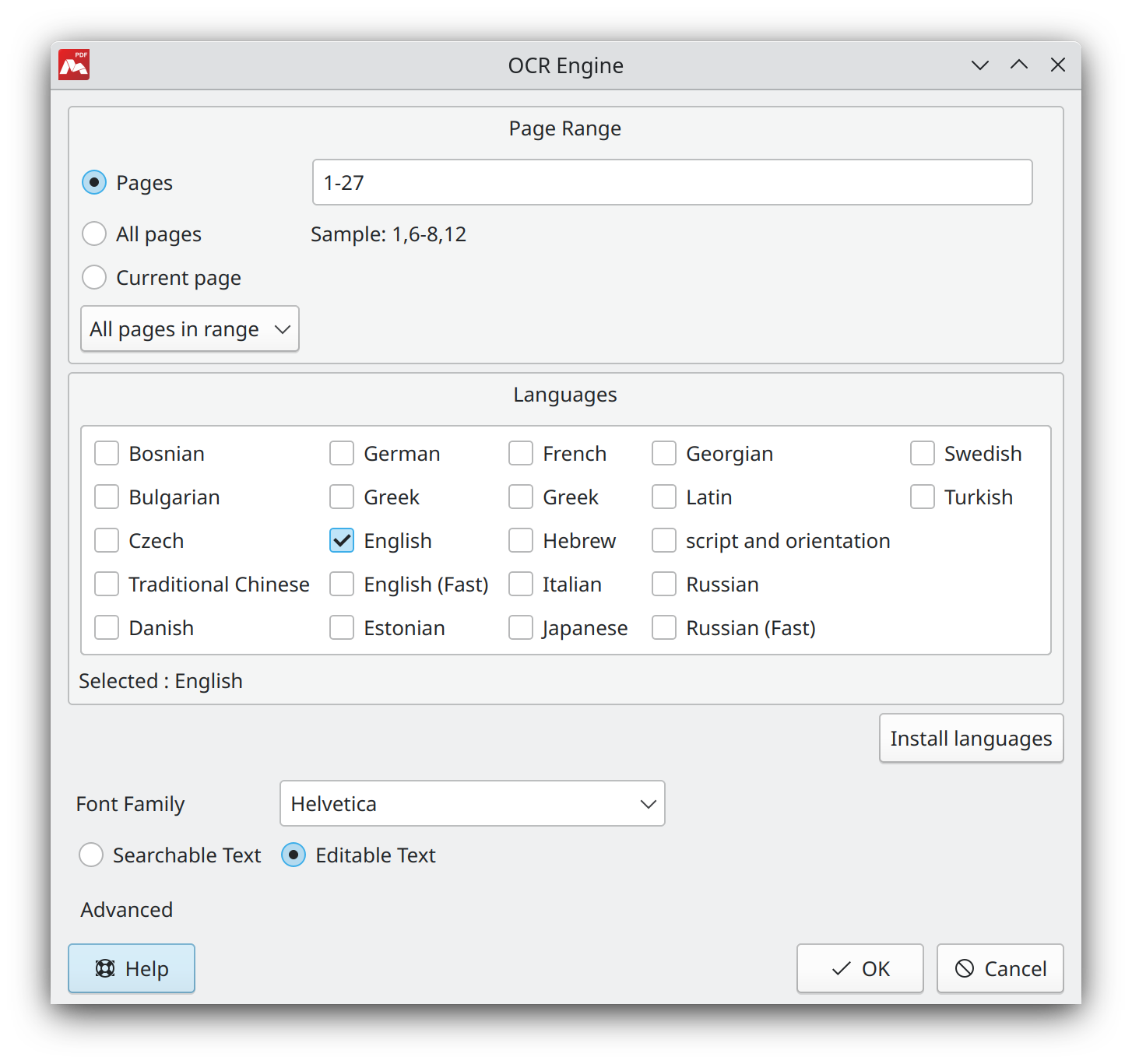
To use optical character recognition, choose Document > OCR menu item. Set the following parameters in the dialogue window:
![]() It’s also possible to install additional languages that are not listed. Place .traineddata file to the Default path to tesseract ocr data files directory specified in the OCR settings. A path to the directory can be changed. Language files can’t be installed in the OCR Engine dialog box, but can be used for text recognition only if a user has no write access to the specified directory containing language files.
It’s also possible to install additional languages that are not listed. Place .traineddata file to the Default path to tesseract ocr data files directory specified in the OCR settings. A path to the directory can be changed. Language files can’t be installed in the OCR Engine dialog box, but can be used for text recognition only if a user has no write access to the specified directory containing language files.
- Page Range. Set pages where optical character recognition must be performed.
- Languages. Set language(s) of recognized text. In order to optimize text recognition quality, it is best to select minimal number of languages.
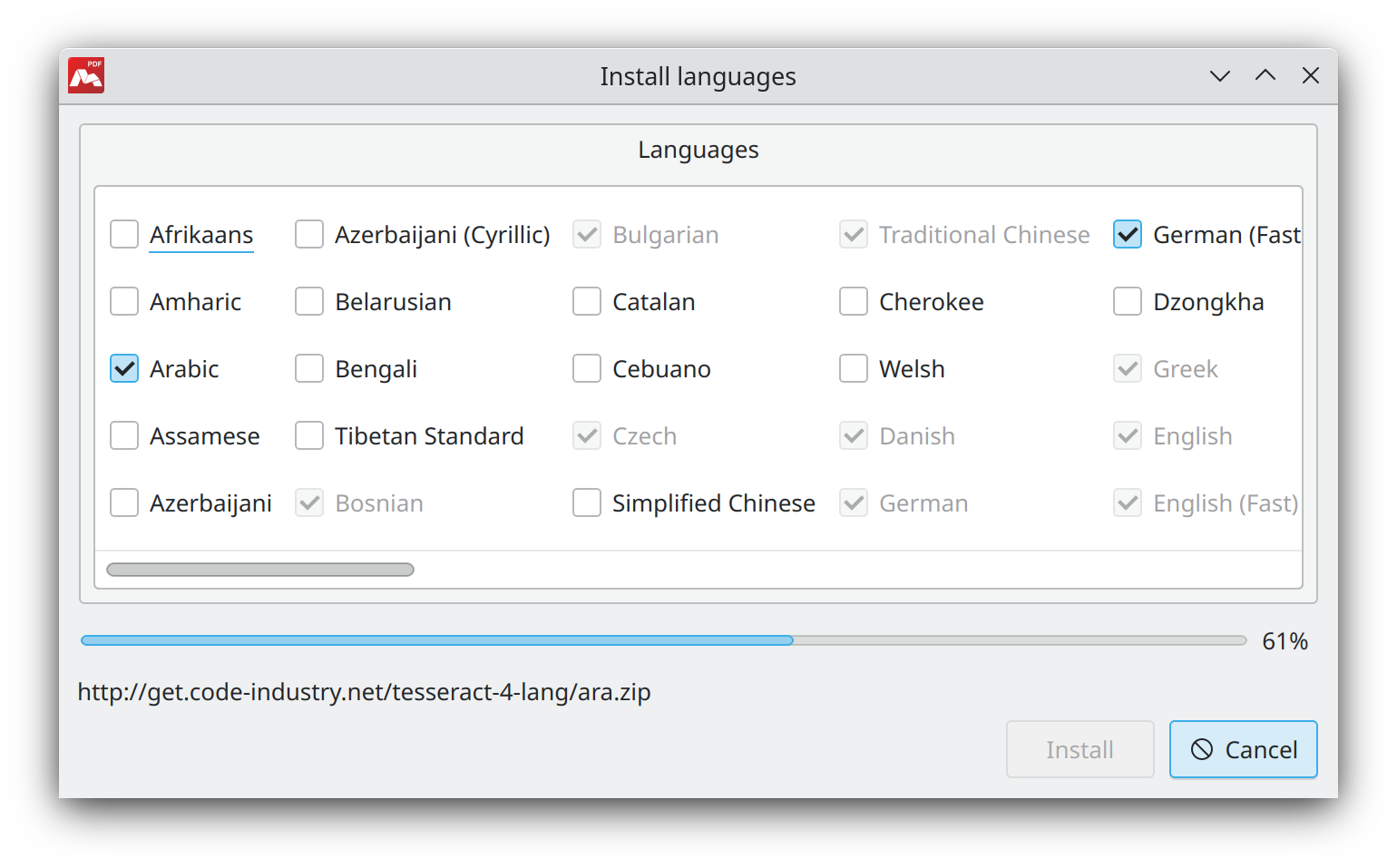
![]() If text recognition is used for the first time, the languages list will be empty. To add languages, press Install languages button.
If text recognition is used for the first time, the languages list will be empty. To add languages, press Install languages button.
- Install languages. Check marks to select required languages. The following window lists languages, which recognition is supported in Master PDF Editor.
- Font Family. Select the predefined font family that will be applied to the recognized text. This option ensures that the font family of the recognized text matches the text in the original document. By default, the font family is set to Helvetica.
- Searchable Text. If this option is selected, recognized text will be available for search and copying only. It will be inserted into the document as an invisible layer under its image.
- Editable Text. With this option, recognized text will be available for editing. The text will be inserted in front of the image that contains it. The image itself will be covered with background color.
You can also set Advanced settings in the OCR Engine window.

- Deskew. Straighten and deskew content on pages automatically when recognizing text. Scanned document content can also be deskewed.
![]() The Deskew option is applicable only to pages with images containing text.
The Deskew option is applicable only to pages with images containing text.
- Minimal confidence level. A numerical value indicating the degree to which the engine is certain that it has recognized the component correctly.
- Force manual text editing if confidence level not achieved. If this option is chosen, a dialog box for text edition will be opened during text recognition. It will display:
- Original. A piece of image with text.
- Text. Automatically recognized text corresponding to the image.
![]() The dialog box Recognized text will successively show each part of the PDF document image with the corresponding recognized text. This allows editing text before inserting it into the document.
The dialog box Recognized text will successively show each part of the PDF document image with the corresponding recognized text. This allows editing text before inserting it into the document.
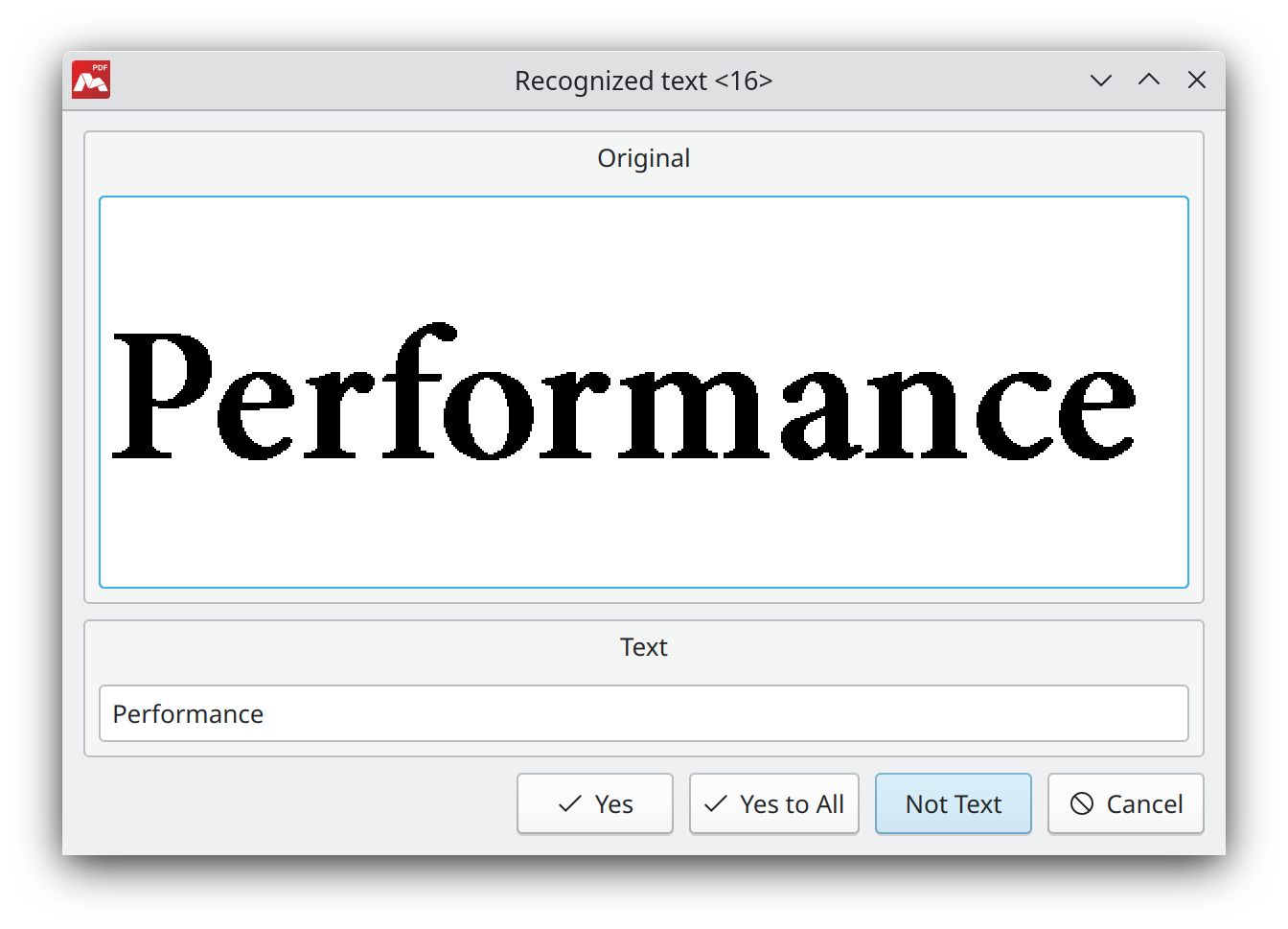
- Yes. Automatically recognized/edited text will be inserted into the document. The dialogue window will display the next image and corresponding text.
- Yes to All. All images will be automatically recognized and written into the document. This dialogue window won’t appear again during this recognition.
- Not Text. The image does not contain text. Cancel text insertion for current image.
- Cancel. Cancel text recognition.
Automatic Text Recognition
Automatic recognition is performed sequentially when navigating through pages.
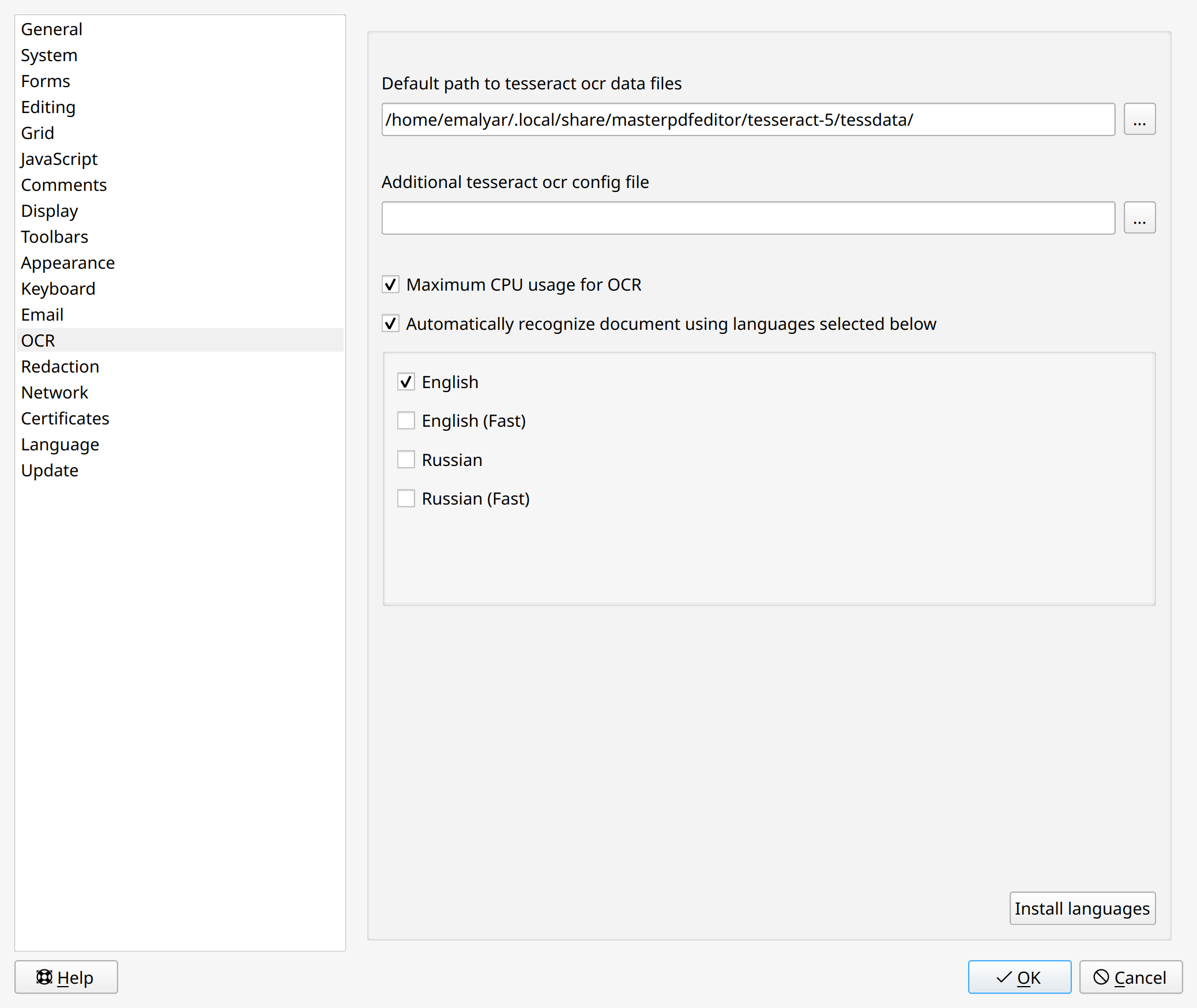
To enable automatic text recognition, check the Automatically recognize text option in the program settings. To do this, navigate to the main menu Settings > Options, and select the Text Recognition tab.
When you select the Document Editing or Hand tools, the automatic text recognition mode is activated.
![]() Once recognition is complete, the text will be available for searching and copying.
Once recognition is complete, the text will be available for searching and copying.
Before starting text recognition, ensure that a language is properly configured. To check, navigate to the main menu Settings > Options, select the Text Recognition tab. Under the Automatically recognize text, select the language to be used for automatic recognition.
![]() Install a language if necessary.
Install a language if necessary.
![]() When Automatically recognize text is enabled, OCR will automatically process pages that contain only images and vector graphic.
When Automatically recognize text is enabled, OCR will automatically process pages that contain only images and vector graphic.
Read more about Master PDF Editor